Last week, Jeff and I had some questions about some specifics about how the BitTorrent protocol works. Over the course of a conversation, I realized that, despite years of using torrents to download Linux ISOs1, I had at best a surface-level understanding of the protocol. That’s a shame, because peer to peer file sharing involves some really neat tech! One of the best ways to understand how something works is to build it, so I wrote a toy BitTorrent client that implements the bare minimum necessary to download a file.
Protocol overview
At a high level, here’s how the BitTorrent protocol works, in the simplest case:
- I browse to Debian’s CD torrent download
page and download
a
.torrentfile, which contains a tracker URL and a list of checksums for the list of pieces I’ll be downloading—all of the information needed to retrieve the actual file. - I import this
.torrentfile into a torrent client. - The client connects to the tracker’s url, provides the SHA1 hash associated with the torrent file. The tracker adds me to its list of peers associated with that hash, and returns to me a list of other peers that may be sharing that file.
- The client connects to those peers, and identify with the hash what file we want to download. When a peer is ready, it “unchokes” us, and begins sending chunks of the file as we request them, typically in a random-ish order.
- Data comes in from as many sources as we can pull from until we have the entirety of the file.
- As a good internet citizen, I continue to seed the file I’ve just received to other peers in the swarm so others are able to download from me.
femtotorrent project scope
If this isn’t the world’s worst BitTorrent client, it must certainly be in the running! That’s okay though; it was only intended to be a learning tool, and not a production-ready software suite.
Features it lacks (in no particular order):
- Support for multi-file torrents
- Support for >4GB torrents
- Support for multiple peers
- Support for peers that don’t have the full file
- Support for peers disconnecting in the middle of the download
- An option to choose where to save the file
- Seeding back to the swarm
- Support for magnet links
- A UI
- Support for torrents that aren’t Debian 11 (hardcoded in)
- Protocol extensions
- Distributed Hash Table – this allows for trackerless torrents
- Peer Exchange
- Any kind of UDP
- Compact peer lists
- A smart choking algorithm for congestion management
Features it has (alphabetized for convenience):
- Can download a file. Usually.
Notes on the protocol
The BitTorrent protocol is brilliant. It’s a great example of software that does what it was designed for incredibly well. It also does it in such a way that, once it exists, makes one say, “Why didn’t I think of that?”. It’s a simple and effective solution that fits its problem domain very well.
The original release of the BitTorrent application was in July
2001.
I, naturally, was closely following every development in the space, having
recently turned four years old at the time. While my commentary is limited by a
lack of context in many ways, I do find it interesting to understand many of the
decisions in context. “Why bencoding? Why not just JSON-encode everything?”
Well, Chandler, you see, JSON didn’t exist yet! (Or, at least,
JSON.org and the JSON spec wouldn’t come to be until
2002. But apparently YAML was already
around2?)
Resources available
Unfortunately, the thing that drew me to implement the BitTorrent spec also ended up being a thorn in my side the whole time I implemented it: The spec, printed, would fit on about five and a half pages. Unfortunately, it’s written in a way that leaves a lot of details ambiguous and hard to understand. For example, one thing that stood out to me as particularly confusing was the specifics on the length prefix on messages. As far as I can tell, quoted here is the entirety of what the protocol doc has to say about message length prefixes:
peer protocol
[…]
The peer wire protocol consists of a handshake followed by a never-ending stream of length-prefixed messages.
[…]
All later integers sent in the protocol are encoded as four bytes big-endian.
[…]
That’s it for handshaking, next comes an alternating stream of length prefixes and messages. Messages of length zero are keepalives, and ignored. Keepalives are generally sent once every two minutes, but note that timeouts can be done much more quickly when data is expected.
peer messages
All non-keepalive messages start with a single byte which gives their type.
I eventually got this figured out, but it took a lot of looking back and forth between my code and the spec to figure out why I wasn’t getting the responses I expected. Some specifics that weren’t obvious:
- To start out, I entirely missed the length prefix note altogether; it’s not grouped with other information that I need to send a message. While the messages are described in some detail ("‘request’ messages contain an index, begin, and length. …"), there’s no mention of the length prefix here.
- How is the length prefix structured?
- Does the length prefix include the length of its own bytes?
- A keepalive isn’t actually of length zero; it includes the length…right?
- If “all non-keepalive messages start with a single byte”, but also all messages start with a length…which comes first?
With the benefit of hindsight, most of this ends up being reasonably clear. I’d been conflating what I was thinking of as a message (“the thing that gets sent across the wire”, possibly Layer 5; includes a length prefix) with what the spec calls a “message” (“the thing after the length prefix that starts with a byte indicating its type”). The length is the length of the message that follows. All perfectly clear now, but far from it on the first many read-throughs!
Also, I was tripped up by two specific points on bencoding that despite repeated
careful reading I can’t find in the spec. First, dicts’ keys must be strings,
which I assumed (because I didn’t want to deal with map[interface]interface{}s
everywhere!) but didn’t see verified. Second, dict keys are ordered
alphabetically.
D’oh! I need to get my vision checked. As I was proofreading this post, I went back to check one more time, and found it, right there, right where I should have been looking, both points, clearly spelled out:
Dictionaries are encoded as a ’d’ followed by a list of alternating keys and their corresponding values followed by an ’e’. For example, d3:cow3:moo4:spam4:eggse corresponds to {‘cow’: ‘moo’, ‘spam’: ’eggs’} and d4:spaml1:a1:bee corresponds to {‘spam’: [‘a’, ‘b’]}. Keys must be strings and appear in sorted order (sorted as raw strings, not alphanumerics).
Credit to the author(s) on this one, I guess!
Other helpful resources
I ended up writing a full first pass at the entirety of the implementation using just the original spec. I deliberately didn’t “cheat” by looking at code from other implementations; this was partially a challenge to myself to see if I could do it from the spec alone.
However, once I had prototyped out the code and started debugging the flaws in my implementation, I ended up being confused on a handful of points, and I did reach out for some additional resources. (Specifically, length prefixes, as I implemented them, included the four bytes of the length prefix as part of the length, causing Transmission, the client on the other end of the connection, to expect more data and not respond.)
Third party documentation turned out to be much more enlightening (and verbose) than the official spec. (https://wiki.theory.org/BitTorrentSpecification in particular is a fantastic resource, and one I’d highly recommend to anyone else looking to implement the protocol.) They provide essentially the same information that the spec does, but more clearly spelled out, and in a way that (to me) was much more obvious on a first read. Particularly, I found their descriptions of choking/unchoking and declaring interest much more enlightening than the original spec’s descriptions.
Wireshark, as recommended by the BitTorrent spec, ended up being very helpful for showing what packets I was sending and receiving, comparing them to a known-good implementation of the spec, and dissecting the parts of the response to validate that my parser was parsing properly.
Interestingly, I would have done a poor job of predicting in advance what resources I would make the most use of. Ol’ reliable, the debugger, barely came into play; my issues for the most part weren’t in understanding what my code was doing, but rather what it was supposed to be doing.
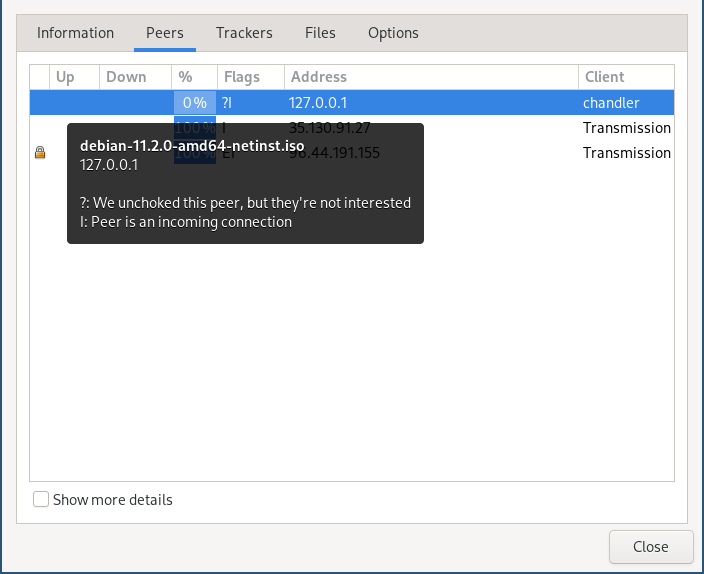
Instead, one of the most (unexpectedly) helpful tools ended up being Transmission, the torrent client I was testing against. The peer list that you get from a client is surprisingly detailed, while still helpful, and (beyond the basics) lists information like whether or not we’re choked or interested, what the state of the connection is, and how much we’ve uploaded/downloaded.
Takeaways
Even though I didn’t come up with a complete implementation, I was able to answer the question I’d had at the beginning: Why don’t BitTorrent trackers get hit by DMCA takedown requests? Turns out, it’s awfully hard to enforce copyright on a map of a 20-byte SHA1 hash to a list of IP addresses (and not even the hash of the tracked file; rather, the hash of some data including hashes of the file’s pieces!). Trackers don’t know the contents of the torrent, nor even the name. (Plus, a torrent can contain multiple trackers, pull peer information from the swarm via DHT, and exchange peer lists with other peers, which in total severely limit the ramifications of a tracker being taken offline, even if it’s legally possible.)
Specifics aside, I wish I had done this years ago! Writing a program from a (simple) spec and getting it to interoperate with other software is a really fun and enlightening project. It was a great way to dive into a problem area I didn’t know much about and learn a bunch about how it works (plus a chance to write lower level code than I often otherwise might!). The protocol wasn’t, perhaps, as nicely specified as I’d have hoped, but it wasn’t bad, either; it’s relatively simple, especially if I’m not trying to implement every feature perfectly.
One of the neat things about having done a few of this type of project is that it really acts as a great confidence booster when I’m considering implementing new protocols. I’d been reading about CardboardWM, and a month ago I never would have considered what it would take to write my own window manager. But now? …maybe that’s next!
-
Normally I’d expect this to be a joke, where “Linux ISOs” is a euphemism for “things I’ve pirated”, but strangely enough in my case it happens to be the truth! I don’t watch much for movies or TV; I use nearly exclusively Free and Open Source Software (including not playing much for games, and I’ll gladly pay for those I do!); and streaming music services have solved the “Piracy is almost always a service problem and not a pricing problem” problem to such a degree that Spotify is worth its cost as a library management tool alone, to say nothing about compensating artists! ↩︎
-
The first draft I could find of the YAML spec was captured by the Internet Archive on March 30, 2001. It bears limited resemblance to modern YAML. Some time later, the YAML editors decided that draft wasn’t worth mentioning, and later editions (linked: the first edition with an example which, upon replacing tabs with spaces, parses as modern YAML) don’t bother mentioning that anything from before May 15 ever existed. ↩︎
