Day 2
I worked my way through the first half of the Emacs tutorial: document navigation, basic text insertion and deletion, cut and paste, and undo/redo. Still no syntax highlighting or anything fancy. I’d guess about two hours for the tutorial, and 20 minutes for writing code.
Part 1 source code
use std::fs;
fn main() {
let data = fs::read_to_string("input.txt").expect("Could not read input.txt");
let data = data.trim();
let mut score = 0;
for line in data.split("\n") {
let choices: Vec<&str> = line.split(" ").collect();
score += match (choices[0], choices[1]) {
("A", "X") => 1 + 3,
("A", "Y") => 2 + 6,
("A", "Z") => 3 + 0,
("B", "X") => 1 + 0,
("B", "Y") => 2 + 3,
("B", "Z") => 3 + 6,
("C", "X") => 1 + 6,
("C", "Y") => 2 + 0,
("C", "Z") => 3 + 3,
_ => panic!("Unknown combination {:?}", choices),
};
}
println!("{}", score);
}
Part 2 source code
use std::fs;
fn main() {
let data = fs::read_to_string("input.txt").expect("Could not read input.txt");
let data = data.trim();
let mut score = 0;
for line in data.split("\n") {
let choices: Vec<&str> = line.split(" ").collect();
score += match (choices[0], choices[1]) {
("A", "X") => 3 + 0,
("A", "Y") => 1 + 3,
("A", "Z") => 2 + 6,
("B", "X") => 1 + 0,
("B", "Y") => 2 + 3,
("B", "Z") => 3 + 6,
("C", "X") => 2 + 0,
("C", "Y") => 3 + 3,
("C", "Z") => 1 + 6,
_ => panic!("Unknown combination {:?}", choices),
};
}
println!("{}", score);
}
Day 3
I completed the rest of the Emacs tutorial: Buffers and buffer manipulation, modes, search, window/frame management, and the help system. I’m definitely feeling a bit more confident in my basic editor usage. Still leaving more advanced editor configuration for tomorrow. I spent about two more hours in the tutorial today, and a hair over 30 minutes writing code.
Part 1 source code
use std::fs;
fn find_duplicated_char(first: &str, second: &str) -> char {
for char in first.chars() {
if second.contains(char) {
return char;
}
}
panic!("no duplicate found");
}
fn priority(c: char) -> u32 {
match c {
'A'..='Z' => c as u32 - 64 + 26,
'a'..='z' => c as u32 - 96,
_ => panic!("This isn't a letter!"),
}
}
fn process(data: &str) -> u32 {
let mut score = 0;
for line in data.split("\n") {
let first_half = &line[0..line.len() / 2];
let second_half = &line[line.len() / 2..line.len()];
score += priority(find_duplicated_char(first_half, second_half));
}
score
}
fn main() {
let data = fs::read_to_string("input.txt").expect("Could not read input.txt");
let data = data.trim();
println!("{}", process(data));
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test() {
let data = "vJrwpWtwJgWrhcsFMMfFFhFp
jqHRNqRjqzjGDLGLrsFMfFZSrLrFZsSL
PmmdzqPrVvPwwTWBwg
wMqvLMZHhHMvwLHjbvcjnnSBnvTQFn
ttgJtRGJQctTZtZT
CrZsJsPPZsGzwwsLwLmpwMDw";
assert_eq!(process(data), 157);
}
}
Part 2 source code
use std::fs;
fn find_duplicated_char(first: &str, second: &str, third: &str) -> char {
for char in first.chars() {
if second.contains(char) && third.contains(char) {
return char;
}
}
panic!("no duplicate found");
}
fn priority(c: char) -> u32 {
match c {
'A'..='Z' => c as u32 - 64 + 26,
'a'..='z' => c as u32 - 96,
_ => panic!("This isn't a letter!"),
}
}
fn process(data: &str) -> u32 {
let mut score = 0;
let lines: Vec<&str> = data.split("\n").collect();
let mut i = 0;
while i < lines.len() {
score += priority(find_duplicated_char(lines[i], lines[i + 1], lines[i + 2]));
i += 3;
}
score
}
fn main() {
let data = fs::read_to_string("input.txt").expect("Could not read input.txt");
let data = data.trim();
println!("{}", process(data));
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test() {
let data = "vJrwpWtwJgWrhcsFMMfFFhFp
jqHRNqRjqzjGDLGLrsFMfFZSrLrFZsSL
PmmdzqPrVvPwwTWBwg
wMqvLMZHhHMvwLHjbvcjnnSBnvTQFn
ttgJtRGJQctTZtZT
CrZsJsPPZsGzwwsLwLmpwMDw";
assert_eq!(process(data), 70);
}
}
Day 4
Today I read the info pages for Dired and figured out that M-! executes shell
commands, so I did the entirety of my work in Rust – no external terminal
needed! I’m still writing the blog post in VS Code, but I’m starting to C-x C-s to save there, which, of course doesn’t work!
Part 1 source code
use std::fs;
fn process(data: &str) -> u32 {
let mut contains_count = 0;
for line in data.split("\n") {
let ranges: Vec<&str> = line.split(",").collect();
let first: Vec<&str> = ranges[0].split("-").collect();
let second: Vec<&str> = ranges[1].split("-").collect();
let first_start: u32 = first[0].parse().unwrap();
let first_end: u32 = first[1].parse().unwrap();
let second_start: u32 = second[0].parse().unwrap();
let second_end: u32 = second[1].parse().unwrap();
if (first_start <= second_start && first_end >= second_end)
|| (second_start <= first_start && second_end >= first_end)
{
contains_count += 1;
}
}
contains_count
}
fn main() {
let data = fs::read_to_string("input.txt").expect("Could not read input.txt");
let data = data.trim();
println!("{}", process(data));
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
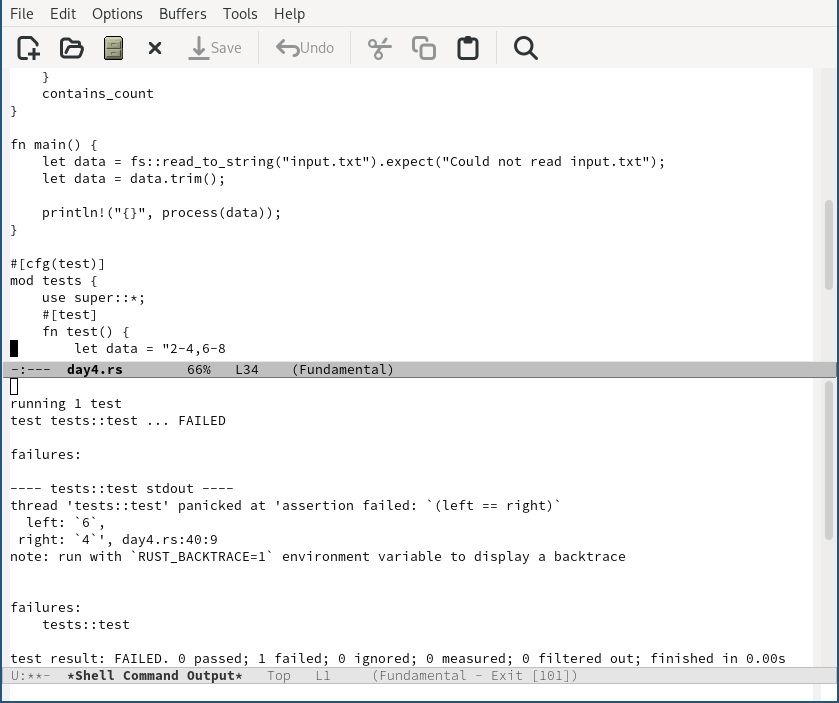
fn test() {
let data = "2-4,6-8
2-3,4-5
5-7,7-9
2-8,3-7
6-6,4-6
2-6,4-8";
assert_eq!(process(data), 2);
}
}
Part 2 source code
use std::fs;
fn process(data: &str) -> u32 {
let mut contains_count = 0;
for line in data.split("\n") {
let ranges: Vec<&str> = line.split(",").collect();
let first: Vec<&str> = ranges[0].split("-").collect();
let second: Vec<&str> = ranges[1].split("-").collect();
let first_start: u32 = first[0].parse().unwrap();
let first_end: u32 = first[1].parse().unwrap();
let second_start: u32 = second[0].parse().unwrap();
let second_end: u32 = second[1].parse().unwrap();
if first_start <= second_end && second_start <= first_end {
contains_count += 1;
}
}
contains_count
}
fn main() {
let data = fs::read_to_string("input.txt").expect("Could not read input.txt");
let data = data.trim();
println!("{}", process(data));
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test() {
let data = "2-4,6-8
2-3,4-5
5-7,7-9
2-8,3-7
6-6,4-6
2-6,4-8";
assert_eq!(process(data), 4);
}
}
Day 5
I didn’t make any meaningful Emacs progress today, other than reading the help
as I needed for specific commands. I’m starting to think about the types of
things I might want in an Emacs config. And I’m reliably C-x C-sing in VS Code
now.
Part 1 source code
use std::collections::VecDeque;
use std::fs;
fn process(data: &str) -> String {
let parts: Vec<&str> = data.split("\n\n").collect();
let mut stack_lines: Vec<&str> = parts[0].split("\n").collect();
stack_lines.truncate(stack_lines.len() - 1); // Remove indexing line
let instructions: Vec<&str> = parts[1].trim().split("\n").collect();
let mut stacks = Vec::new();
for _ in 0..(stack_lines[0].len() + 1) / 4 {
stacks.push(VecDeque::new());
}
for line in stack_lines {
for i in 0..stacks.len() {
let c = line.chars().nth(i * 4 + 1).unwrap();
if c != ' ' {
stacks[i].push_back(c);
}
}
}
for instruction in instructions {
let instruction: Vec<&str> = instruction.split(" ").collect();
let source: usize = instruction[3].parse().unwrap();
let target: usize = instruction[5].parse().unwrap();
for _ in 0..instruction[1].parse().unwrap() {
let c = stacks[source-1].pop_front().unwrap();
stacks[target-1].push_front(c);
}
}
stacks.iter().map(|s| s.front().unwrap()).collect()
}
fn main() {
let data = fs::read_to_string("input.txt").unwrap();
println!("{}", process(&data));
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test() {
let data = " [D]
[N] [C]
[Z] [M] [P]
1 2 3
move 1 from 2 to 1
move 3 from 1 to 3
move 2 from 2 to 1
move 1 from 1 to 2";
assert!(process(data) == "CMZ");
}
}
Part 2 source code
use std::collections::VecDeque;
use std::fs;
fn process(data: &str) -> String {
let parts: Vec<&str> = data.split("\n\n").collect();
let mut stack_lines: Vec<&str> = parts[0].split("\n").collect();
stack_lines.truncate(stack_lines.len() - 1); // Remove indexing line
let instructions: Vec<&str> = parts[1].trim().split("\n").collect();
let mut stacks = Vec::new();
for _ in 0..(stack_lines[0].len() + 1) / 4 {
stacks.push(VecDeque::new());
}
for line in stack_lines {
for i in 0..stacks.len() {
let c = line.chars().nth(i * 4 + 1).unwrap();
if c != ' ' {
stacks[i].push_back(c);
}
}
}
for instruction in instructions {
let instruction: Vec<&str> = instruction.split(" ").collect();
let source: usize = instruction[3].parse().unwrap();
let target: usize = instruction[5].parse().unwrap();
for i in 0..instruction[1].parse().unwrap() {
let c = stacks[source-1].pop_front().unwrap();
stacks[target-1].insert(i, c);
}
}
stacks.iter().map(|s| s.front().unwrap()).collect()
}
fn main() {
let data = fs::read_to_string("input.txt").unwrap();
println!("{}", process(&data));
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test() {
let data = " [D]
[N] [C]
[Z] [M] [P]
1 2 3
move 1 from 2 to 1
move 3 from 1 to 3
move 2 from 2 to 1
move 1 from 1 to 2";
assert!(process(data) == "MCD");
}
}
Day 6
Today was the first day that I was a bit stumped writing code. The uniqueness check took a while to ponder through, but I got it working in just under an hour. Again, no major progress on anything Emacs-related.
Source code
use std::fs;
fn process(data: &str, len: usize) -> usize {
let chars: Vec<char> = data.chars().collect();
for i in len..chars.len() {
let mut chars = chars[i-len..i].to_vec(); // TODO: this seems unidiomatic?
chars.sort();
chars.dedup();
if chars.len() == len {
// no duplicates
return i;
}
}
panic!("No valid marker found");
}
fn main() {
let data = fs::read_to_string("input.txt").unwrap();
let data = data.trim();
println!("{}", process(data, 14)); // 4 for part A
}
#[cfg(test)]
mod test {
use super::*;
#[test]
fn test_short() {
let data = vec![
("mjqjpqmgbljsphdztnvjfqwrcgsmlb", 7),
("bvwbjplbgvbhsrlpgdmjqwftvncz", 5),
("nppdvjthqldpwncqszvftbrmjlhg", 6),
("nznrnfrfntjfmvfwmzdfjlvtqnbhcprsg", 10),
("zcfzfwzzqfrljwzlrfnpqdbhtmscgvjw", 11),
];
for (datum, result) in data {
assert!(process(datum, 4) == result);
}
}
#[test]
fn test_long() {
let data = vec![
("mjqjpqmgbljsphdztnvjfqwrcgsmlb", 19),
("bvwbjplbgvbhsrlpgdmjqwftvncz", 23),
("nppdvjthqldpwncqszvftbrmjlhg", 23),
("nznrnfrfntjfmvfwmzdfjlvtqnbhcprsg", 29),
("zcfzfwzzqfrljwzlrfnpqdbhtmscgvjw", 26),
];
for (datum, result) in data {
assert!(process(datum, 14) == result);
}
}
}
Day 7
I finally installed rust-mode. I’m
not sure why I waited so long—this was incredibly simple. M-x package-install rust-mode and then M-x rust-mode had me in
syntax-highlighted, working-indentation paradise1 in a
grand total of maybe three minutes. (This only works in Emacs 28 and later,
which includes the nongnu ELPA repos, and,
therefore, rust-mode).
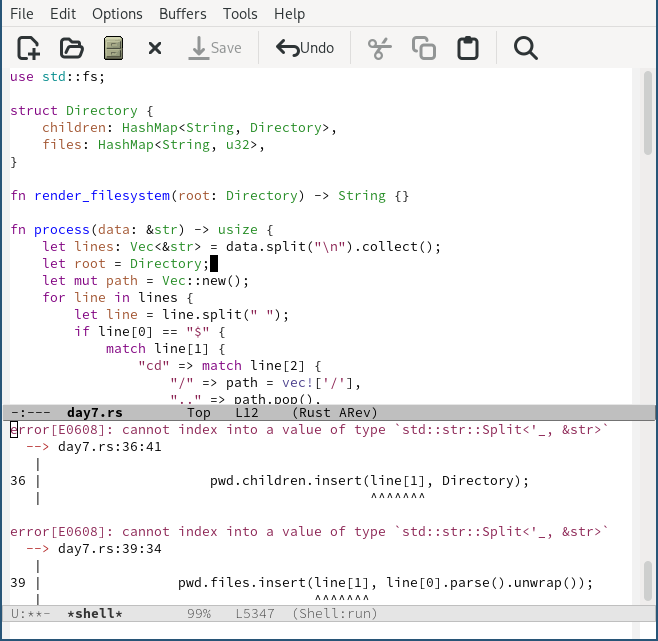
This problem took me quite a long time; I spent a lot of time figuring out how
to best parse this data, and then a lot of additional time fighting
negotiating with the borrow checker. A first iteration involved mutual
references (e.g. for directories A and B, with B a subdirectory of A,
A would have B in its list of children, and B would have A listed for
its parent ("..")), which doesn’t work. I looked into
Rc and
RefCells, but ended up coming
up with a moderately straightforward implementation that didn’t use either. I
also had an epiphany about how borrowing works that finally (after an
embarrassingly long time) made my mental model of the borrow checker click into
place. So, all in all, definitely worth the struggle today!
I’d guess this puzzle took me three to four hours of intermittent work, over three days, which is why this post came out a bit later than targeted. Hopefully now that this one is done, I’ll be back on track going forward!
Source code
use std::collections::HashMap;
use std::fs;
struct Directory {
children: HashMap<String, Directory>,
files: HashMap<String, u32>,
}
impl Directory {
fn size(&self) -> u32 {
let mut size = 0;
for (_name, child) in &self.children {
size += child.size();
}
for (_name, file_size) in &self.files {
size += file_size;
}
size
}
fn directories_at_most_size(&self, size: u32) -> u32 {
let mut count = if self.size() <= size { self.size() } else { 0 };
for (_name, child) in &self.children {
count += child.directories_at_most_size(size);
}
count
}
fn smallest_directory_at_least(&self, target_size: u32) -> u32 {
let mut size = u32::MAX;
if self.size() < size && self.size() >= target_size {
size = self.size();
}
for (_name, child) in &self.children {
let child_size = child.smallest_directory_at_least(target_size);
if child_size < size && child_size >= target_size {
size = child_size;
}
}
size
}
}
fn process(data: &str) -> u32 {
let lines: Vec<&str> = data.split("\n").collect();
let mut root = Directory {
children: HashMap::new(),
files: HashMap::new(),
};
let mut path = Vec::new();
for line in lines {
let line: Vec<&str> = line.split(" ").collect();
if line[0] == "$" {
match line[1] {
"cd" => match line[2] {
"/" => path = Vec::new(),
".." => path.truncate(path.len() - 1),
dir => path.push(dir),
},
"ls" => {}
_ => panic!("Unknown command"),
}
} else {
// Part of `ls` output
let mut pwd = &mut root;
for dir in path.iter() {
pwd = pwd.children.get_mut(&dir.to_string()).unwrap();
}
if line[0] == "dir" {
if pwd.children.contains_key(line[1]) {
println!("We've seen {} before", line[1]);
} else {
pwd.children.insert(
line[1].to_string(),
Directory {
children: HashMap::new(),
files: HashMap::new(),
},
);
}
} else {
pwd.files
.insert(line[1].to_string(), line[0].parse().unwrap());
}
}
}
let size_available = 70_000_000 - root.size();
let size_needed = 30_000_000 - size_available;
root.smallest_directory_at_least(size_needed) // directories_at_most_size() for part 1
}
fn main() {
let data = fs::read_to_string("input.txt").unwrap();
let data = data.trim();
println!("{}", process(data));
}
#[cfg(test)]
mod test {
use super::*;
static DATA: &str = "$ cd /
$ ls
dir a
14848514 b.txt
8504156 c.dat
dir d
$ cd a
$ ls
dir e
29116 f
2557 g
62596 h.lst
$ cd e
$ ls
584 i
$ cd ..
$ cd ..
$ cd d
$ ls
4060174 j
8033020 d.log
5626152 d.ext
7214296 k";
#[test]
fn test() {
assert!(process(DATA) == 24933642); // 95437 for part 1
}
}
Notes
At this point, I’m maintaining a bit of a checklist of things I want to figure out how to do in Emacs, and I’m making a bit of progress:
- Use
Diredinstead of a terminal or file manager - Rust syntax highlighting1
- Rust display errors inline
- Fix wonky indentation (partially—spaces/tabs are still mixed)
- Run
rustfmtautomatically?
- Run
- Single key combination to compile and run binary
- Git integration within Emacs, without falling back to
M-x shell - Modify config file (aka learn elisp)
- Set
auto-revert-modeby default (useful for e.g.rustfmt)
- Set
I’ve really grown to like a lot of things about Emacs:
- Emacs’ help system is incredible. The tutorial is great, and the
documentation available for anything I could want to do is somewhere in
C-h. Apropos is nice; having explainers for each key combo withC-h k; it’s all fantastic. - Emacs’ built-in shell works really nicely. (Vim gained a terminal in
8.1, but I never got along too
well with it.) There are lots of integrations that work really nicely. I was
particularly impressed when
gitasked for an SSH key passphrase, and Emacs prompted me in the minibuffer for the passphrase so that it wouldn’t be echoed in the terminal. - In addition to being a very capable terminal editor, it’s also nicely integrated with the desktop. Copy/paste works fine with Wayland, and the mouse works nicely, and having a list of menus and icons, while I don’t use them heavily, is rather convenient.
I’ll note, to be fair to Vim, that I was never quite this intentional about learning its features. Most everything I’m able to do this far, I was also able to do in Vim, or would have been able to figure out how to, had I wanted.
Soundtrack






-
Maybe I’m just becoming an old grouch, but having not had syntax highlighting for much of the week, I honestly don’t miss it as much as I thought I would. I often find it useful for finding trivial syntax errors (“I didn’t close a quote” being a common one), and I suppose to some extent as an additional visual cue for navigation, but I didn’t really find either of those to be significantly impeding here. ↩︎ ↩︎
-
Cory Wong is on Bandcamp! Here’s The Golden Hour. I 10/10 recommend both Cory Wong and Bandcamp: wicked awesome guitar, and DRM-free no-nonsense FLAC music downloads, respectively. ↩︎
